

探索的データ解析とは
予め仮説を立てた上でデータを収集し、解析を行うことは非常に重要です。事前に仮説を設定し、得られたデータセットを用いて仮説を検証することを仮説検証的研究と言います。一方で、得られたデータセットから新たに仮説を見出そうとすることは仮説探索的研究と言います。
仮説探索的研究ではまずデータセットの特徴を把握する事が必要です。ある程度の目星をつけて網羅的に解析を行うことを探索的データ解析(Exploratory data analysis; EDA)と言います。EDAを行うことは新たに仮説を立てるためだけでなく、より良いモデル構築の前処理や仮説検証の補助としても大いに役立ちます。
一方でEDAでは網羅的に解析を行う必要があるため、多くの手間と時間がかかってしまいます。しかし、Pythonライブラリを利用することでデータセットを簡便に処理する事が可能です。
EDAが可能なPythonライブラリ
EDAのためのPythonライブラリは下記のようなものがあります。
・ Pandas-Profiling
・ D-tale
・ Sweetviz
今回は多くの特徴量を持つデータ(医療データなど)を解析にかけても処理が軽く、視認性が優れていたSweetvizを紹介したいと思います。本ページでは jupyter notebook を利用しHTMLで出力します。
Sweetvizの利用法
EDAのライブラリは共通してPandasをベースに使用しています。
pipを利用してインストールしておきます。
pip install pandas
pip install sweetviz
データセットはKaggleのTitanic号データをサンプルとして使用します。
SweetvizではTraining dataとTest dataを同時に解析し、比較して表示することも可能ですが、今回はTraining dataを titanic.csvとリネームして記載します。
まずはPandasとSweetvizをインポートします。
import pandas as pd
import sweetviz as sv
Sweetviz : 1つのデータセットを読み込む場合
Sweetvizにcsvファイルを読み込ませます。単独のcsv fileを読み込むだけなら下記でOKです。”titanic.csv”の部分を任意のcsvファイルネームに差し替えてください。Current directory内にHTMLファイルが出力されます。
#Using Sweetviz
sweet_report = sv.analyze(pd.read_csv(“titanic.csv”))
#Saving results
sweet_report.show_html(‘titanic.csv.html’)
以下は実行結果のHTMLを開いた画面です。
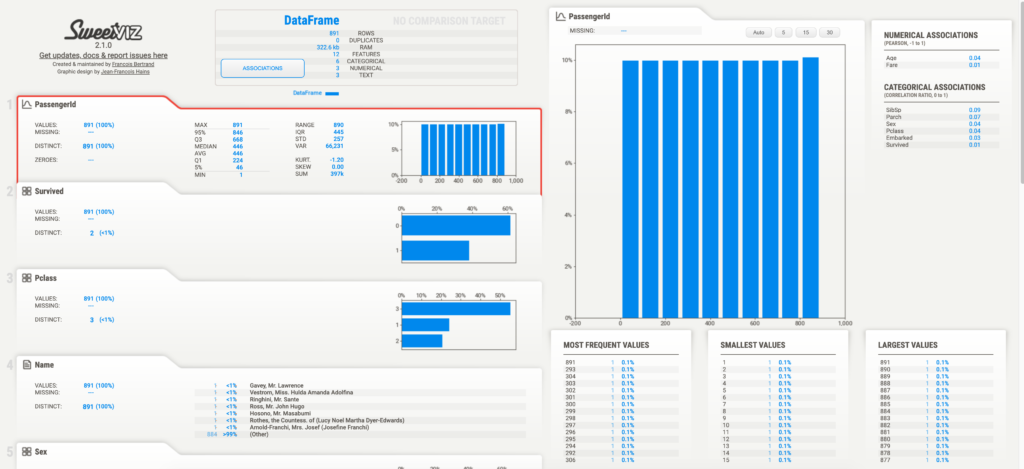
各特徴量の分布や基本統計に加えて、他の特徴量との相関係数の表示(連続量、カテゴリカル変数を分けて)が可能な他、データの欠損率も表示する事が可能です。
画面左上のAssociationをクリックしてみてください。
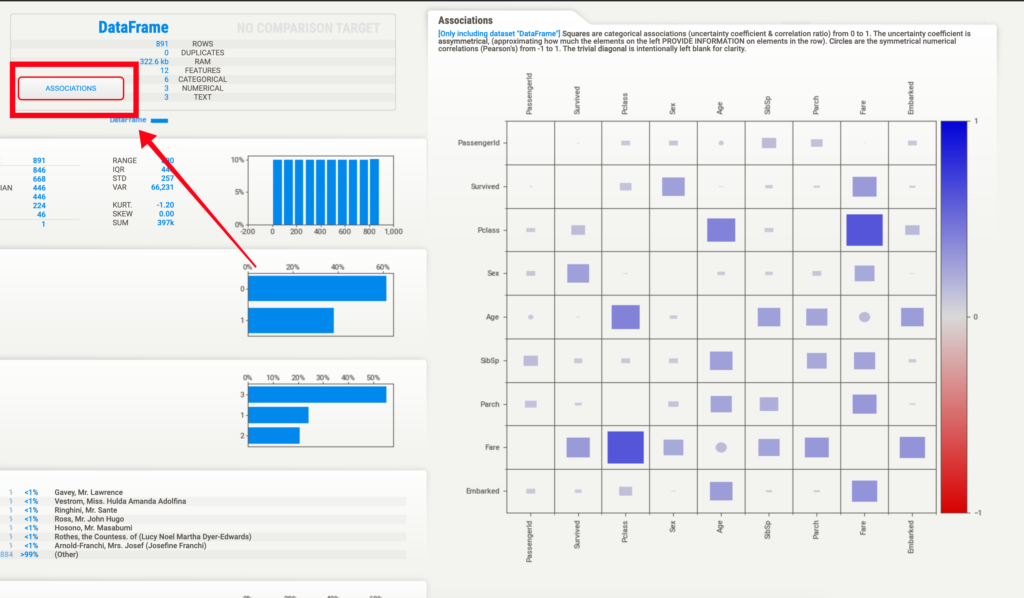
右半分の画面にHeat mapが表示され、ひと目でデータの関係性が確認できます。
Sweetviz : 2つのデータセットを比較する
Training dataとTest dataを読み込む、2つの施設のデータを比較したいといった時にもSweetvizは便利です。下記コードで2つのデータセットを読み込みましょう。
例に漏れず、”titanic_train.csv” と “titanic_test.csv”は任意のcsv fileに変更してください。
#Using Sweetviz (compare)
df_train = pd.read_csv(“titanic_train.csv”)
df_test = pd.read_csv(“titanic_test.csv”)
sweet_report = sv.compare([df_train, “Train”], [df_test, “Test”])
#Saving results
sweet_report.show_html(‘titanic_compare.csv.html’)
以下、実行結果の画面です。
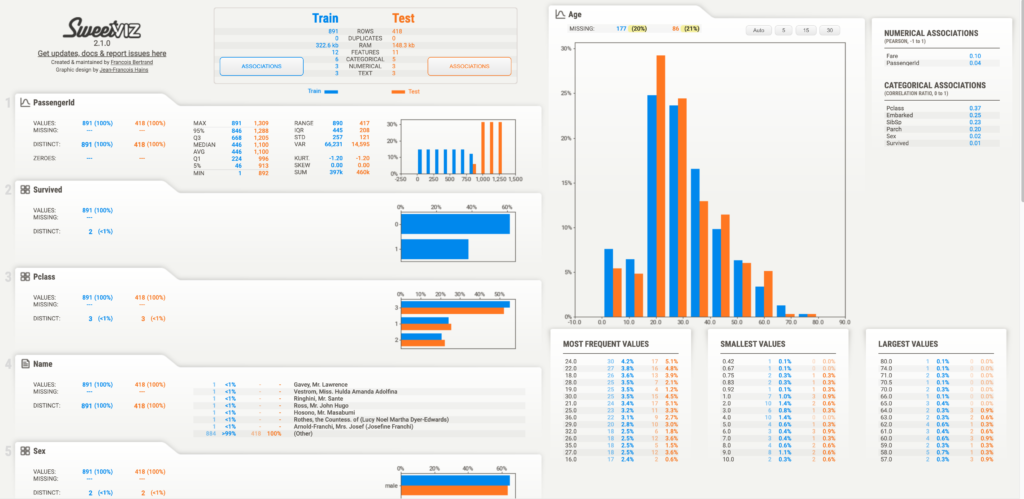
先ほどと同様の画面で、データの比較が可能になっている事がわかると思います。
まとめ
Sweetvizを用いる事でデータセットに対するEDAを簡便に行う事ができました。
データセットを触る前にEDAを行い、特徴を把握することは非常に重要です。ぜひ試してみてください。







コメント