

医療など説明性が求められる分野においては、機械学習・分類モデルにおける特徴量の重要度評価についての検討が必要と思います。また、医学論文のStudyではデータに対して複数のモデルを作成し、比較する手法を取ることが多いです。
本ページでは “scikit-learn” を用いて作られる古典的機械学習モデルにおいて、特徴量の重要度を評価する方法にどのようなものがあるのか、機械学習を用いたStudyを組んだ際に重要度評価としてどの方法を選択すべきかを考察します。
特徴量重要度の評価法には以下のものが挙げられます。
・Gain Importance (Gini impyrity)
・Permutation Importance
・LIME (local interpretable model-agnostic explanations)
・SHAP (SHapley Additive exPlanations)
個々のモデルについて簡単にまとめます。実装については別ページをご参照ください。
Gain Importance (Gini impurity)
Gain Importanceはツリー系モデルで用いることができる重要度評価法です。
ざっくりとまとめると、決定木の各階層(ノード)がモデルの精度を規定する Impurity; 不純度を下げることにどれだけ寄与したか、を計算することで算出しているようです。
ただし、ツリーの階層が深くなればなるほど、上位ノードの重要度は相対的に大きくなるため、定量的に解釈することはできません。また因子間に交絡がある場合、個々の重要度が低く算出される可能性があるようです。
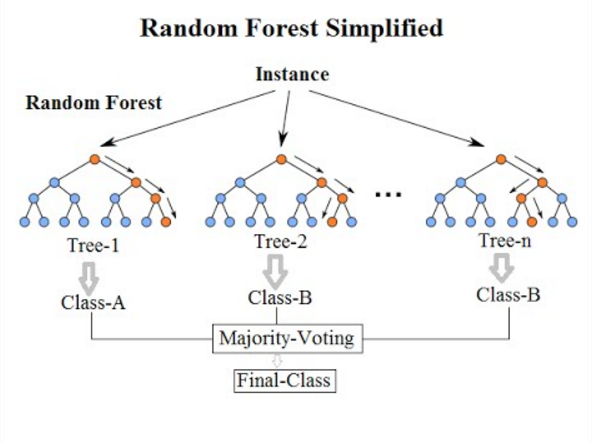
ツリー系モデルとしては Random forrest, XGBoost, Light GBM などが挙げられます。これらはそれぞれ決定木をアンサンブル学習(複数のモデルを作成し学習)させたモデルです。アンサンブル学習には並列して学習させる “バギング” と直列に学習させる “ブースティング” があり、バギングベースのものがRandom forrest、ブースティングベースのものが XGBoost と Light GBM になります。
メリットとして、Feature Importanceは Scikit-learn APIにデフォルトで搭載されているため、比較的簡便に利用できます。一方でサポートベクターマシン (Support vector machine; SVM)や k近傍法(k-Nearest Neighbor; k-NN)などを含めた、ツリー系以外のモデルでは使用できません。
Permutation Importance
Permutation Importanceは、ある特徴量のデータをランダムに並び替える(=ある特徴量がモデルに寄与しなくなる)ことにより、変化したモデルの精度から逆説的に特徴量重要度を算出する方法です。そのため ”アルゴリズムに依存せずに” 重要度を評価することができます。
ただPermutation Importanceでは、一つの特徴量を無効化して評価するという側面上、相関の高い複数の特徴量の重要度が低く算出される可能性があります。(片方の特徴量を無効化しても、もう一方の特徴量が学習精度を担保するため。)
Scikit-learn モデルに利用する際には ” eli5 “ というパッケージでも導入できますが、Ver.0.23.2 現在、Scikit-learn パッケージ自体にもデフォルトで搭載されています。
下記は参考サイトです。

LIME (local interpretable model-agnostic explanations)
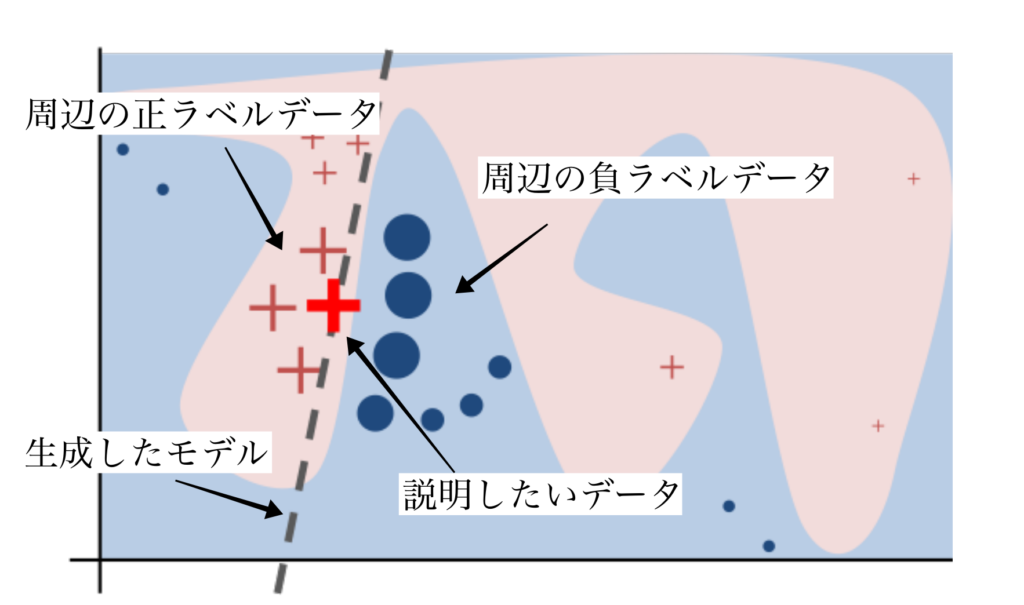
LIMEは説明したいデータ (対象の特徴量)の周囲のデータをサンプリングすることで、線形モデルを作成しモデル自体の説明性を向上させる、というコンセプトです。
下図は元論文から引用したものです。ピンクのエリアを正ラベルデータの集合、青のデータを負ラベルデータの集合とすると、全体を線形回帰モデルとして解析することは不可能です。
そのため説明対象となるデータの周辺にのみ着目し、線形モデルで近似した上でその係数を比較することで特徴量の重要度を評価します。
LIMEを用いることができるデータはTable形式、テキストデータ、画像イメージのいずれにも対応しています。
Pythonで導入しScikit-learnモデルへの実装が可能です。

SHAP (SHapley Additive exPlanations)
SHAPは “協力ゲーム理論” のShapley valueを用いて各特徴量がモデルにどれだけ寄与しているか解釈する手法です。LIMEと同様、古典的機械学習からDeepLearningまで複数のモデルに対応しています。
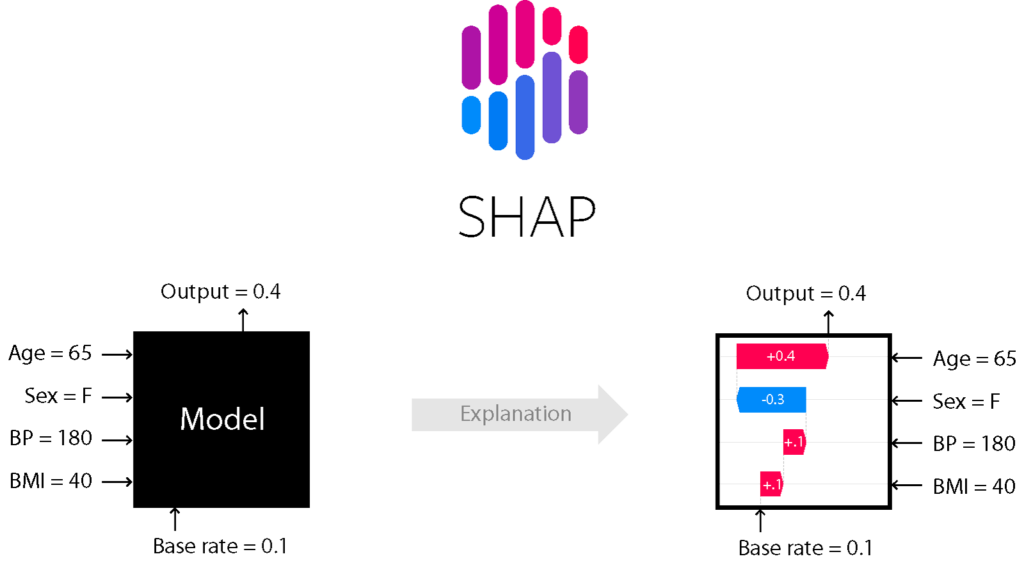
SHAPでは解析するモデルに応じてアルゴリズムを切り替え、解析を行うことができます。GitHubにそれぞれノートブックが公開されているので試してみましょう。
- TreeExplainer
-
Scikit-learnで実装可能な XGBoostやLightGBMといったツリーアンサンブルモデルで解析可能です。
- DeepExplainer
- GradientExplainer
-
TensorflowやKerasで実装したDeep Learningモデルを解析するためのアルゴリズムです。
- KernelExplainer
-
線形回帰を利用してSupport Vector Machineを含めた任意のモデルで解析が可能です。
本記事の目的とは離れますが、Deep learningの特徴量重要性について検討する場合はLIMEとSHAPが選択肢に挙がり、SHAPの方が用いられている印象です。
まとめ
Kaggleコンペティションでは “より良い予測値を出す” ことが目的のため、モデル構築・特徴量の前処理からアンサンブルまでがメインタスクになると思います。
一方で医学論文においては機械学習を用いたStudyでも “Studyから得られたデータ” 自体が最も重要であるため同様のデータを複数のモデルに組み込み、モデル同士を比較した上で考察するという手法が取られることが多いです。
実際に論文化された内容で重要度評価のアプローチについて明確に記載されているものは少なく、使われている評価法について統計的に検討したわけではありません。
しかし特徴量自体にアプローチし重要度評価を行うという点で、解析段階におけるモデル間で差異が少ない(と考えられる)Permutation Importanceから用い、他の評価アルゴリズムについても検討するのが良いのではないでしょうか。







コメント